后端——问题小书(2021)
rehoni / 2021-12-29
问题1:Cannot forward to error page for request
具体描述
Cannot forward to error page for request [/wechat/portal] as the response has already been commit
解决方案和原理
使用response输出流或@ResponseBody
response.getWriter().print(echostr);
@responseBody注解的作用是将controller的方法返回的对象通过适当的转换器转换为指定的格式之后,写入到response对象的body区,通常用来返回JSON数据或者是XML数据,需要注意的呢,在使用此注解之后不会再走试图处理器,而是直接将数据写入到流中,他的效果等同于通过response对象输出指定格式的数据。
因此可知之前直接使用return echostr spring会找不到对应的视图,但是视图找不到,spring又转到errorPage,但是项目中没有配置errorPage,从而404.
问题2、文件上传功能报错
具体描述
Current request is not a multipart request
解决方案和原理
是postmapping而不是getmapping
@ApiOperation(value = "测试图片上传")
@PostMapping(value = "/upload")
public Result handleFileUpload(@RequestParam List<MultipartFile> files) {
return Result.buildSuccess(
storageService.storeByString(files)
).setMsg("You successfully uploaded " + files.size() + "files !");
}
问题3、httpClient警告
具体描述
Warning:“Going to buffer response body of large or unknown size.Using getResponseBodyAsStream instead isrecommended.”
解决方案和原理
字面意思,稍微大的文件建议以流的方式而不是字符串的方式来读取body,解决方案:getResponseBodyAsStream替代getResponseBodyAsString。
try (InputStream input = postMethod.getResponseBodyAsStream();
BufferedReader br = new BufferedReader(new InputStreamReader(input, charSet))) {
String temp;
StringBuilder sb = new StringBuilder();
while ((temp = br.readLine()) != null) {
sb.append(temp);
}
resultMap.put("responseSoap", sb.toString());
} catch (UnsupportedEncodingException e) {
log.error("获取请求返回报文失败,不支持的编码异常",e);
} catch (IOException e) {
log.error("获取请求返回报文失败,I/O异常",e);
}
问题4、SocketInputStream报错
具体描述
排查到报错在statusCode = httpClient.executeMethod(postMethod);这一句,怀疑是要下载的xml文件过大(>40M),导致socketRead0问题。
15-Jul-2020 10:01:47.926 警告 [localhost-startStop-2] org.apache.catalina.loader.WebappClassLoaderBase.clearReferencesThreads Web应用程序[imp-ws]似乎启动了一个名为[pool-2-thread-1]的线程,但未能停止它。这很可能会造成内存泄漏。线程的堆栈跟踪:[
java.net.SocketInputStream.socketRead0(Native Method)
java.net.SocketInputStream.socketRead(Unknown Source)
java.net.SocketInputStream.read(Unknown Source)
java.net.SocketInputStream.read(Unknown Source)
java.io.BufferedInputStream.fill(Unknown Source)
java.io.BufferedInputStream.read(Unknown Source)
org.apache.commons.httpclient.HttpParser.readRawLine(HttpParser.java:78)
org.apache.commons.httpclient.HttpParser.readLine(HttpParser.java:106)
org.apache.commons.httpclient.HttpConnection.readLine(HttpConnection.java:1116)
org.apache.commons.httpclient.HttpMethodBase.readStatusLine(HttpMethodBase.java:1973)
org.apache.commons.httpclient.HttpMethodBase.readResponse(HttpMethodBase.java:1735)
org.apache.commons.httpclient.HttpMethodBase.execute(HttpMethodBase.java:1098)
org.apache.commons.httpclient.HttpMethodDirector.executeWithRetry(HttpMethodDirector.java:398)
org.apache.commons.httpclient.HttpMethodDirector.executeMethod(HttpMethodDirector.java:171)
org.apache.commons.httpclient.HttpClient.executeMethod(HttpClient.java:397)
org.apache.commons.httpclient.HttpClient.executeMethod(HttpClient.java:323)
解决方案和原理
- 对连接时间和读取时间的超时设置长些,2. 指定通过webservice获取的xml文件的条件,限定到具体的天,使得xml文件的内容变少。
// 1. 超时时间设置
int statusCode = 0;
try {
// 连接超时
httpClient.getHttpConnectionManager().getParams().setConnectionTimeout(60000);
// 读取超时
httpClient.getHttpConnectionManager().getParams().setSoTimeout(60000);
statusCode = httpClient.executeMethod(postMethod);
resultMap.put("statusCode", statusCode);
} catch (IOException e) {
e.printStackTrace();
}
// 2. webservice请求头条件
soap.append(" <soa:AllConditions>\\n");
soap.append(" <Condition>\\n");
condition.accept(soap);
soap.append(" </Condition>\\n");
soap.append(" </soa:AllConditions>\\n");
问题5、springboot项目在服务器上启动非常慢
具体描述
在本地调试的时候druiddatasource启动之后,在requestmap日志出来之前要卡很久,
解决方案和原理
结合之前丢服务器的tomcat上有mapper报错的问题,比对mapper泛型里的实体,发现实体和数据库的字段有个没有对上,导致出现了这个问题,注释掉多出来的字段就行。
问题6、spring bean名称重复
具体描述
根据报错可以知道,cameraServiceImpl的名称重复了,generate文件夹和customize文件夹下都有这个
Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException: Annotation-specified bean name 'cameraServiceImpl' for bean class [com.nrec.pcs9000.app.service.generate.impl.CameraServiceImpl] conflicts with existing, non-compatible bean definition of same name and class [com.nrec.pcs9000.app.service.customize.impl.CameraServiceImpl]
解决方案和原理
修改bean的名字即可
@Service(value = "customCameraServiceImpl")
public class CameraServiceImpl implements CameraService {
问题7、StringRedisTemplate 根据key前缀批量删除key
-
根据指定的key前缀 + “"( 号一定要有),查询出所有匹配到的key
-
调用StringRedisTemplate 的 delete 方法,把当前获取到的指定前缀key的集合传进去
Set<Object> keys = stringKeyRedisTemplate.keys(keyType + "*");
assert keys != null;
Long delete = stringKeyRedisTemplate.delete(keys);
log.info("取消【{}】类型的所有的守望位缓存共【{}】个", keyType, delete);
return delete;
问题8、String像log一样用{}填充
hutool的strUtil已有实现,StrUtil.format,具体可以参照hutool文档
if (oldKeepWatch == null) {
return Result.build(keepWatchService.insert(keepWatch),
StrUtil.format("【{}】变电站【{}】下监控点【{}】主站守望位", "新增", camera.getRegion(), camera.getCamera())
);
}
if (keepWatch.getEnable().equals(0)) {
return Result.build(keepWatchService.updateById(keepWatch),
StrUtil.format("【{}】变电站【{}】下监控点【{}】主站守望位", "关闭", camera.getRegion(), camera.getCamera())
);
} else {
return Result.build(keepWatchService.updateById(keepWatch),
StrUtil.format("【{}】变电站【{}】下监控点【{}】主站守望位", "修改", camera.getRegion(), camera.getCamera())
);
}
问题9、通过反射将Map转为实体并且获取service实现入库
利用Hutool的反射工具类 ReflectUtil 获取service,和实体工具类 BeanUtil 转化map为Bean
@Override
public void test() throws ClassNotFoundException {
// 1、读取excel读取为Map列表,默认第一行为标题行,Map中的key为标题,value为标题对应的单元格值;
// 2、从数据库把配置数据读取出来,步骤1中的数据,把map中的中文标题key转为英文字段key;
List<Map<String, Object>> mapList = new ArrayList<>();
HashMap<String, Object> objMap1 = new HashMap<>();
objMap1.put("indexCode", "111");
objMap1.put("preset",1);
HashMap<String, Object> objMap2 = new HashMap<>();
objMap2.put("indexCode", "222");
objMap2.put("preset",2);
mapList.add(objMap1);
mapList.add(objMap2);
// 3、步骤2转化后的Map列表,根据表名,通过反射转为对应的entity列表;
Class<?> entityClass = Class.forName("com.nrec.pcs9000.app.entity.CameraKeepWatch");
List<Object> entityList = new ArrayList<>();
for (Map<String, Object> map : mapList) {
// Object o = BeanUtil.fillBeanWithMap(map, entityClass.newInstance(), true);
Object entity = BeanUtil.toBean(map, entityClass);
entityList.add(entity);
}
// 4、根据表名,反射获取对应的serviceImpl,实现entity列表入库
Object beanService = SpringUtil.getBean("cameraKeepWatchServiceImpl");
ReflectUtil.invoke(beanService, "insertOrUpdateBatch", entityList);
}
问题10、Java泛型中E、T、K、V等含义
Java泛型中的标记符含义:
E - Element (在集合中使用,因为集合中存放的是元素)
T - Type(Java 类)
K - Key(键)
V - Value(值)
N - Number(数值类型)
? - 表示不确定的java类型
S、U、V - 2nd、3rd、4th types
问题12、dom4j解析xml【已发布】
dom4j获取iterator
/**
* @author luohao
* @create 2020/6/18 17:21
*/
@Slf4j
public class Dom4jUtils {
public static Iterator<Element> getElementIterator(String path) {
SAXReader reader = new SAXReader();
Document document = null;
try {
document = reader.read(new File(path));
} catch (DocumentException e) {
log.error("Dom4j:读取xml文件时异常{}", e.getMessage(), e);
}
Optional<Document> docElementOpt = Optional.ofNullable(document);
return docElementOpt.map(Document::getRootElement).map(Element::elementIterator).orElseGet(() -> new Iterator<Element>() {
@Override
public boolean hasNext() {
return false;
}
@Override
public Element next() {
return null;
}
});
}
}
获取xml的node节点和属性
/**
* @param path 文件路径
* @param list 用于基本信息表的数据list
* @param list1 用于详细信息表的数据list
*/
private static void extractXml(String path, List<Map<String, Object>> list, List<Map<String, Object>> list1) {
Iterator<Element> it = Dom4jUtils.getElementIterator(path);
// 遍历迭代器,获取根节点中的信息(书籍)
while (it.hasNext()) {
Map<String, Object> map = new HashMap<>();
// 存放一个主键
String stationNameVal = "";
String checkTimeVal = "";
Element node = it.next();
// 塞入巡检报告基本信息表(IFR_CHECKREPORT_BASEINFO)
if ("System".equals(node.getName())) {
// 迭代一次
Iterator<Element> itt = node.elementIterator();
while (itt.hasNext()) {
Element nodeChild = itt.next();
// 转换substation的key
if ("Substation".equals(nodeChild.getName())) {
map.put("StationName", nodeChild.getStringValue());
stationNameVal = nodeChild.getStringValue();
} else if ("CheckTime".equals(nodeChild.getName())) {
map.put("CheckTime", nodeChild.getStringValue());
checkTimeVal = nodeChild.getStringValue();
} else {
map.put(nodeChild.getName(), nodeChild.getStringValue());
}
}
}
// 塞入巡检报告概要结果表(IFR_CHECKREPORT_DETAILINFO)
else if ("Ied".equals(node.getName())) {
// 迭代两次
Iterator<Element> itt = node.elementIterator();
while (itt.hasNext()) {
Element nodeChild = itt.next();
Map<String, Object> map1 = new HashMap<>();
// 在map1里边存入一个主键
map1.put("StationName", stationNameVal);
map1.put("CheckTime", checkTimeVal);
// 获取nodeChild的attrs
List<Attribute> attrs = nodeChild.attributes();
for (Attribute attr : attrs) {
if ("IsChecked".equals(attr.getName())) {
map1.put("DeviceIsChecked", attr.getValue());
} else if ("UnCheckedReason".equals(attr.getName())) {
map1.put("DeviceUnCheckReason", attr.getValue());
} else if ("result".equals(attr.getName())) {
map1.put("DeviceResult", attr.getValue());
} else {
map1.put(attr.getName(), attr.getValue());
}
}
Iterator<Element> ittt = nodeChild.elementIterator();
while (ittt.hasNext()) {
Element nodeChild1 = ittt.next();
// 获取nodeChild1的attrs
List<Attribute> attrs1 = nodeChild1.attributes();
for (Attribute attr : attrs1) {
if ("result".equals(attr.getName())) {
map1.put(nodeChild1.getName() + "Result", attr.getValue());
} else {
map1.put(nodeChild1.getName() + attr.getName(), attr.getValue());
}
}
}
list1.add(map1);
}
} else {
// 详细报告不录入,之后再改
break;
}
if (map.size() > 0) {
list.add(map);
}
}
}
问题13、map和bean互转【已发布】
Map转为Bean
public <T, K, V> T map2Bean(Map<K, V> map, Class<T> beanCls) {
// try catch未写
T t = null;
BeanInfo beanInfo = Introspector.getBeanInfo(beanCls.getClass());
PropertyDescriptor[] propertyDescriptors = beanInfo.getPropertyDescriptors();
t = beanCls.newInstance();
for (PropertyDescriptor property : propertyDescriptors) {
String key = property.getName();
if (map.containsKey(key)) {
Object value = map.get(key);
Method setter = property.getWriteMethod();
setter.invoke(t, value);
}
}
return t;
}
Bean转为Map
public <T, K, V> Map<String, Object> bean2Map(T bean) {
// try catch未写
Map<String, Object> map = new HashMap<>();
if (bean == null) {
return null;
}
BeanInfo beanInfo = Introspector.getBeanInfo(bean.getClass());
PropertyDescriptor[] propertyDescriptors = beanInfo.getPropertyDescriptors();
for (PropertyDescriptor property : propertyDescriptors) {
String key = property.getName();
if (!"class".equalsIgnoreCase(key)) {
Method getter = property.getReadMethod();
Object value = getter.invoke(bean);
map.put(key, value);
}
}
return map;
}
问题14、创建不可变并且static静态集合【已发布】
findbugs错误提示
MS_MUTABLE_COLLECTION_PKGPROTECT, Priority: Normal
XX.XX.XXX.XX is a mutable collection which should be package protected
A mutable collection instance is assigned to a final static field, thus can be changed by malicious code or by accident from another package. The field could be made package protected to avoid this vulnerability. Alternatively you may wrap this field into Collections.unmodifiableSet/List/Map/etc. to avoid this vulnerability.
很容易写的一个错误案例如下:
public class TestMap {
private static final Map<Integer,String> map = new LinkedHashMap<Integer, String>();
static {
map = new HashMap();
map.put(1, "one");
map.put(2, "two");
}
}
正确的做法 ,通过Collections.unmodifiableMap。
public class TestMap {
private static final Map<Integer,String> map ;
static {
Map<Integer,String> tempMap = new HashMap();
tempMap.put(1, "one");
tempMap.put(2, "two");
map = Collections.unmodifiableMap(tempMap);
}
}
如果现在往map里添加元素,则抛出UnsupportedOperationException异常
问题15、实现文件监听
hutool有具体实现
- 支持多级目录的监听(WatchService只支持一级目录),可自定义监听目录深度
- 延迟合并触发支持(文件变动时可能触发多次modify,支持在某个时间范围内的多次修改事件合并为一个修改事件)
- 简洁易懂的API方法,一个方法即可搞定监听,无需理解复杂的监听注册机制。
- 多观察者实现,可以根据业务实现多个
Watcher来响应同一个事件(通过WatcherChain)
监听指定事件
File file = FileUtil.file("example.properties");
//这里只监听文件或目录的修改事件
WatchMonitor watchMonitor = WatchMonitor.create(file, WatchMonitor.ENTRY_MODIFY);
watchMonitor.setWatcher(new Watcher(){
...
}
//设置监听目录的最大深入,目录层级大于制定层级的变更将不被监听,默认只监听当前层级目录
watchMonitor.setMaxDepth(3);
//启动监听
watchMonitor.start();
监听全部事件
WatchMonitor.createAll(file, new SimpleWatcher(){
@Override
public void onModify(WatchEvent<?> event, Path currentPath) {
Console.log("EVENT modify");
}
}).start();
延迟处理监听事件
在监听目录或文件时,如果这个文件有修改操作,JDK会多次触发modify方法,为了解决这个问题,我们定义了DelayWatcher,此类通过维护一个Set将短时间内相同文件多次modify的事件合并处理触发,从而避免以上问题。
WatchMonitor monitor = WatchMonitor.createAll("d:/", new DelayWatcher(watcher, 500));
monitor.start();
问题16、各时间类的转换【已发布】
LocalDateTime和Long的转换
fun transform() {
val localDateTime = LocalDateTime.now()
// LocalDateTime to LocalDate
println(localDateTime.toLocalDate())
// LocalDateTime to Instant
println(localDateTime.toInstant(ZoneOffset.UTC))
// LocalDateTime to Long
println(localDateTime.toInstant(ZoneOffset.UTC).toEpochMilli())
val localDate = LocalDate.now()
// LocalDate to LocalDateTime
println(localDate.atTime(LocalTime.now()))
// LocalDate to Instant
println(localDate.atTime(LocalTime.now()).toInstant(ZoneOffset.UTC))
// LocalDate to Long
println(localDate.atTime(LocalTime.now()).toInstant(ZoneOffset.UTC).toEpochMilli())
val instant = Instant.now()
// Instant to LocalDateTime
println(LocalDateTime.ofInstant(instant, ZoneId.systemDefault()))
// Instant to LocalDate
println(LocalDate.ofInstant(instant, ZoneId.systemDefault()))
// Instant to Long
println(instant.toEpochMilli())
val milli: Long = Instant.now().toEpochMilli()
// Long to LocalDateTime
println(LocalDateTime.ofInstant(Instant.ofEpochMilli(milli), ZoneId.systemDefault()))
// Long to LocalDate
println(LocalDate.ofInstant(Instant.ofEpochMilli(milli), ZoneId.systemDefault()))
// Long to Instant
println(Instant.ofEpochMilli(milli))
}
LocalDateTime和String的转换
// LocalDateTime转为String
String string = LocalDateTime.now().format(new DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSSSSS"));
// String转为LocalDateTime
String time = "2020-07-08 14:41:50.238473";
LocalDateTime parse = LocalDateTime.parse(time, new DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss.SSSSSS"));
java.util.Date和String的转换
SimpleDateFormat格式化进行转换
// java.util.Date转换String
DateFormat dateFormat = new SimpleDateFormat("dd-MM-yy:HH:mm:ss");
Date date = new Date();
String dateStr = dateFormat.format(date);
// String转换java.util.Date
try {
DateFormat dateFormat = new SimpleDateFormat("dd/MM/yyy");
Date date = dateFormat.parse(dateStr);
} catch (ParseException e) {
e.printStack();
}
java.sql.Timestamp和String的转换
与java.util.Date和String的转换类似,都是通过SimpleDateFormat格式化进行转换,不展开代码细讲。
java.util.Date和java.sql.Timestamp的转换
//Date转换Timestamp
Timestamp timestamp = new Timestamp((new Date()).getTime());
//Timestamp转换Date,二者是父子关系,可以直接赋值,自动转换
Timestamp timestamp1 = new Timestamp(System.currentTimeMillis());
Date date = new Date(timestamp1.getTime());
timestamp的比较
before和after函数,可以参考源码内的实现,compareTo接口。
Timestamp a = Timestamp.valueOf("2018-05-18 09:32:32");
Timestamp b = Timestamp.valueOf("2018-05-11 09:32:32");
if (b.before(a)) {
System.out.println("b时间比a时间早");
}
before函数中封装了compareTo函数,在compareTo(Timestamp t)中对传入的Timestamp做比较。通过long thisTime = this.getTime();获取的时间戳进行比较,compareTo(Date u)也可以传入java.util.Date,不过也是对其做Timestamp的转换后调用compareTo(Timestamp t)做的处理。
问题17、打包资源文件压缩不可用
1、获取文件流
获取来自IDEA的项目resources目录下的defect-template.docx这个word文件模板,并且生成word
private void generateWord(File file, List<PatrolDefectDto> list, HashMap<String, Object> headerMap) throws UnsupportedEncodingException {
Resource docxRes = resourceLoader.getResource("classpath:defect-template.docx");
// 表格主体
List<Map<String, Object>> tables = getTables(list);
HashMap<String, Object> paramMap = new HashMap<>(headerMap);
paramMap.put("tables", tables);
try {
XWPFTemplate.compile(docxRes.getInputStream()).render(paramMap).writeToFile(file.getAbsolutePath());
} catch (IOException e) {
e.printStackTrace();
}
String fileFinish = file.getAbsolutePath().replace("start", "finished");
file.renameTo(new File(fileFinish));
}
2、压缩文件过滤
如果把压缩好的war包/jar包解压缩,打开包里的word文件发现损坏,基本确定是maven install 打包的时候导致文件压缩不可用的原因了!只需要在pom中加入以下配置即可解决
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<version>2.6</version>
<artifactId>maven-resources-plugin</artifactId>
<configuration>
<encoding>UTF-8</encoding>
<nonFilteredFileExtensions>
<nonFilteredFileExtension>docx</nonFilteredFileExtension>
</nonFilteredFileExtensions>
</configuration>
</plugin>
</plugins>
问题18、数组拼接去除最后的分号
代码片段
public static void main(String[] args) {
List<String> list = Arrays.asList("a", "b", "c", "d", "end");
StringBuilder sb = new StringBuilder();
for (String s : list) {
sb.append(s).append(",");
}
sb.delete(sb.length() - 1, sb.length());
System.out.println("StringBuilder的做法:" + sb);
System.out.println("Commons lang3的做法:" + StringUtils.join(list, ","));
}
输出
StringBuilder的做法:a,b,c,d,end
Commons lang3的做法:a,b,c,d,end
问题19、线程定时得到结果退出示例【已发布】
大致需求
定时每几秒调用一次rest接口,如果接口响应成功则退出线程,如果接口响应失败,则继续调用直至成功。
做了一个简单的线程任务。简单来说是一个异步的调用方式。目前采用的方式是设置一个flag,作为判断rest接口是否调用成功的结果标志位,接口调用不成功则线程死循环;接口调用成功则线程不进入while,退出。
public static void main(String[] args) {
// 线程沉睡时间,每3秒试图调用一次接口插入到告警表
final long timeInterval = 3000;
AtomicBoolean flag = new AtomicBoolean(false);
Thread thread = new Thread(() -> {
while (!flag.get()) {
flag.set(testFlag());
try {
Thread.sleep(timeInterval);
} catch (InterruptedException e) {
log.info("thread sleep interrupted");
}
}
});
thread.start();
}
private static boolean testFlag() {
int code = 500;
boolean fl = false;
try {
if (code == 500) {
throw new NullPointerException();
} else if (code == 200) {
log.info("code = 200,存入数据库");
fl = true;
}
} catch (Exception e) {
log.info("未获得code");
return false;
}
return fl;
}
Connected to the target VM, address: '127.0.0.1:51619', transport: 'socket'
15:38:56.445 [Thread-0] INFO com.nrec.pcs9000.app.task.RobotLinkageTask - 未获得code
15:38:59.450 [Thread-0] INFO com.nrec.pcs9000.app.task.RobotLinkageTask - 未获得code
15:39:02.451 [Thread-0] INFO com.nrec.pcs9000.app.task.RobotLinkageTask - 未获得code
15:39:05.452 [Thread-0] INFO com.nrec.pcs9000.app.task.RobotLinkageTask - 未获得code
15:39:08.453 [Thread-0] INFO com.nrec.pcs9000.app.task.RobotLinkageTask - 未获得code
15:39:25.722 [Thread-0] INFO com.nrec.pcs9000.app.task.RobotLinkageTask - code = 200,存入数据库
Disconnected from the target VM, address: '127.0.0.1:51619', transport: 'socket'
需求升级
在原有需求上考量,如果接口持续调用失败,那新开的线程则一直不会退出。一段时间内产生的线程要是足够多,说不定导致所有的线程不会退出,JVM宕机。因此在原有的基础上加一个固定的超时需求。
定时每几秒调用一次rest接口,如果接口响应成功则退出线程,如果接口响应失败,则继续调用直至成功。如果接口响应一直失败,则在固定的时间内超时退出。
// 线程沉睡时间,每6秒试图调用一次接口插入到告警表
ExecutorService executor = Executors.newSingleThreadExecutor();
final long timeInterval = 6000;
AtomicBoolean flag = new AtomicBoolean(false);
Future<Boolean> future = executor.submit(() -> {
while (!flag.get()) {
flag.set(getAndInsertTaskPatrolledId(headerParameters, taskCode, stationCode));
try {
Thread.sleep(timeInterval);
} catch (InterruptedException e) {
log.info("线程中断,退出");
return false;
}
}
// 注意这里也是false,退出while之后线程也是结束的
return false;
});
try {
log.info("开始获取机器人任务运行状态");
// 10分钟超时时间
future.get(600, TimeUnit.SECONDS);
log.info("获取机器人任务运行状态成功,已存入数据库!");
} catch (TimeoutException e) {
future.cancel(true);
log.info("线程超时结束!");
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
executor.shutdownNow();
问题20、关于日志配置
slf4j-log4j12日志的种类
Slf4j,log4j2,log4j,logging,logback等多种日志手段。
Maven项目引入log4j2
1、普通Maven项目
pom.xml
- 单独引入日志
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
- 引入日志门面,配合hutool工具集
Hutool-log对于日志框架的监测顺序是: Slf4j(Logback) > Log4j > Log4j2 > Apache Commons Logging > JDK Logging > Console当然,如果只是引入Slf4j-API,而没有引入任何实现,Slf4j将被跳过。
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.3.7</version>
</dependency>
log4j.properties
resources目录下log4j.properties
log4j.rootLogger=DEBUG,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Threshold=DEBUG
log4j.appender.console.ImmediateFlush=true
#log4j.appender.console.Target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern= %-5p %d(%r) [%t] %c %L %M - %m%n
或者可以
log4j.rootLogger=debug,STDOUT
log4j.additivity.org.apache=true
log4j.appender.STDOUT=org.apache.log4j.ConsoleAppender
log4j.appender.STDOUT.layout=org.apache.log4j.PatternLayout
log4j.appender.STDOUT.layout.ConversionPattern=[%d{HH:mm:ss,SSS}][%5p] %c:%L - %m%n
2、Spring boot的Maven项目
- spring boot 本身有带logging日志
- spring boot的log4j2依赖
- lombok自带log4j2
问题21、jdbc基本
1. 连接池
连接池创建好固定数量的连接,数据库操作通过借用连接池的连接来进行操作,并且不关闭而是返还给连接池。
2. try-with-resources
实现autoClosable接口的类,均可以进行try-with-resources的操作。
close的顺序是,先进后出,类似堆栈。
try (Connection c = DriverManager.getConnection("jdbc:mysql://127.0.0.1:3306/how2java?characterEncoding=UTF-8","root", "admin");
Statement s = c.createStatement();) {
String sql = "select * from hero where id = " + id;
ResultSet rs = s.executeQuery(sql);
// 因为id是唯一的,ResultSet最多只能有一条记录
// 所以使用if代替while
if (rs.next()) {
hero = new Hero();
String name = rs.getString(2);
float hp = rs.getFloat("hp");
int damage = rs.getInt(4);
hero.name = name;
hero.hp = hp;
hero.damage = damage;
hero.id = id;
}
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
3. ORM
ORM=Object Relationship Database Mapping
对象和关系数据库的映射
简单说,一个对象,对应数据库里的一条记录
4. DAO
DAO=DataAccess Object
数据访问对象
实际上就是运用了练习-ORM中的思路,把数据库相关的操作都封装在这个类里面,其他地方看不到JDBC的代码。通过设计类实现DAO接口,来完成对特定类的CRUD操作。
- 把驱动的初始化放在了构造方法里
- 提供
getConnection方法返回连接
package jdbc;
import java.util.List;
import charactor.Hero;
public interface DAO{
//增加
public void add(Hero hero);
//修改
public void update(Hero hero);
//删除
public void delete(int id);
//获取
public Hero get(int id);
//查询
public List<Hero> list();
//分页查询
public List<Hero> list(int start, int count);
}
改造jdbc工具类
增删改
可以设置一个Object数组,用来占位Preparement的sql里的那些?,数组的长度就是预插入的值的数量,数组里的值就是可以录入到Preparestatement的值。
//我们发现,增删改只有SQL语句和传入的参数是不知道的而已,所以让调用该方法的人传递进来
//由于传递进来的参数是各种类型的,而且数目是不确定的,所以使用Object[]
public static void update(String sql, Object[] objects) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = getConnection();
preparedStatement = connection.prepareStatement(sql);
//根据传递进来的参数,设置SQL占位符的值
for (int i = 0; i < objects.length; i++) {
preparedStatement.setObject(i + 1, objects[i]);
}
//执行SQL语句
preparedStatement.executeUpdate();
} catch (Exception e) {
e.printStackTrace();
}
}
查询
注意这里可以定义一个接口,对select的结果集进行操作,但是不知道需要具体进行操作,调用接口的实现类,接口就可以调用实现的方法。
/*
1:对于查询语句来说,我们不知道对结果集进行什么操作【常用的就是把数据封装成一个Bean对象,封装成一个List集合】
2:我们可以定义一个接口,让调用者把接口的实现类传递进来
3:这样接口调用的方法就是调用者传递进来实现类的方法。【策略模式】
*/
//这个方法的返回值是任意类型的,所以定义为Object。
public static Object query(String sql, Object[] objects, ResultSetHandler rsh) {
Connection connection = null;
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
connection = getConnection();
preparedStatement = connection.prepareStatement(sql);
//根据传递进来的参数,设置SQL占位符的值
if (objects != null) {
for (int i = 0; i < objects.length; i++) {
preparedStatement.setObject(i + 1, objects[i]);
}
}
resultSet = preparedStatement.executeQuery();
//调用调用者传递进来实现类的方法,对结果集进行操作
return rsh.hanlder(resultSet);
}
}
接口
/*
* 定义对结果集操作的接口,调用者想要对结果集进行什么操作,只要实现这个接口即可
* */
public interface ResultSetHandler {
Object hanlder(ResultSet resultSet);
}
实现示例
//接口实现类,对结果集封装成一个Bean对象
public class BeanHandler implements ResultSetHandler {
//要封装成一个Bean对象,首先要知道Bean是什么,这个也是调用者传递进来的。
private Class clazz;
public BeanHandler(Class clazz) {
this.clazz = clazz;
}
@Override
public Object hanlder(ResultSet resultSet) {
try {
//创建传进对象的实例化
Object bean = clazz.newInstance();
if (resultSet.next()) {
//拿到结果集元数据
ResultSetMetaData resultSetMetaData = resultSet.getMetaData();
for (int i = 0; i < resultSetMetaData.getColumnCount(); i++) {
//获取到每列的列名
String columnName = resultSetMetaData.getColumnName(i+1);
//获取到每列的数据
String columnData = resultSet.getString(i+1);
//设置Bean属性
Field field = clazz.getDeclaredField(columnName);
field.setAccessible(true);
field.set(bean,columnData);
}
//返回Bean对象
return bean;
}
}
}
}
问题22、Java文件时间排序
File[] files = FileUtil.file(img).listFiles();
Arrays.sort(files, (o1, o2) -> {
long diff = o1.lastModified() - o2.lastModified();
if (diff > 0) return 1;
else if (diff == 0) return 0;
else return -1;
});
问题23、Java方法重载中遇到的编译器错误
当两个重载函数的参数如下时:ide会出现编译错误 both methods have same erasure
public <T> void getData(List<Map<String, Object>> dataList, Class<T> classs, OracleConnection con);
// 要加入的函数,报错 both methods have same erasure
public <T> void getData(List<T> dataList, Class<T> classs, OracleConnection con)
由于Java泛型在编译时擦除类型之后,上述方法会变成 void getData(List dataList)。
1. type erasure的本质
泛型(T) –> 编译器(type erasure) –> 原始类型(T被Object替换) 泛型(? extends XXX) –> 编译器(type erasure) –> 原始类型(T被XXX替换) 原始类型指被编译器擦除了泛型信息后,类型变量在字节码中的具体类型。
2. type erasure导致泛型的局限性
类型擦除降低了泛型的泛化性,使得某些重要的上下文环境中不能使用泛型类型,具有一定的局限性。
-
运行时隐含类型转换的开销: 使用泛型时,Java编译器自动帮我们生成了类型转换的代码,这相对于C++模板来说无疑带来了额外的性能开销。
-
重载方法签名冲突
-
一个类不能实现同一个泛型接口的两种变体
应该考虑在设计之初就进行List的写法,从而能够实现高拓展性。Java泛型:类型擦除(type erasure)有对泛型做一个通识性的讲解。
问题23、JavaSplit小数点的时候需要转义
if ("name".equalsIgnoreCase(fieldName)) {
if (!value.toString().isEmpty() && value != null && functionType == 1) {
String names = value.toString();
return names.split("\\.")[1]; // 横山站.110kV#1主变
}
}
问题24、Java对数字的替换
// outlet_count110kv ---> outlet_count_110kv
String patterns = "outlet_count[1,2,3,5][1,2,5,0][0,5]{0,1}kv";
if (Pattern.matches(patterns, sb.toString())) {
return sb.toString().replaceFirst("[0-9]", "_$0");
} else {
return sb.toString();
}
问题25、Java的split拆分文件路径
用了正则,匹配\和/两个
String[] pathArray = remotePath.split("[\\\\/]");
问题26、SAXParseException报错
Caused by: org.xml.sax.SAXParseException:元素内容必须由格式正确的字符数据或标记组成。
and PLAN_START_TIME >= date_format(#{startTime},'%Y-%m-%d %H:%i:%s')
and PLAN_START_TIME &It;= date_format(#{startTime},'%Y-%m-%d %H:%i:%s')
用<;代替小于号,用>;代替大于号
问题27、mybatis-plus3的ew带where问题
${ew.customSqlSegment}带where
${ew.sqlSegment}不带where
注意看源码中getCustomSqlSegment的实现,能够发现customSqlSegment在sqlSegment的基础上拼接了where
public String getCustomSqlSegment() {
MergeSegments expression = this.getExpression();
if (Objects.nonNull(expression)) {
NormalSegmentList normal = expression.getNormal();
String sqlSegment = this.getSqlSegment();
if (StringUtils.isNotBlank(sqlSegment)) {
if (normal.isEmpty()) {
return sqlSegment;
}
return "WHERE " + sqlSegment;
}
}
return "";
}
问题28、redisTemplate设置和获取缓存过期时间
设置和获取过期时间
// 设置过期时间,两种方式
stringKeyRedisTemplate.opsForValue().set(key, preset);
stringKeyRedisTemplate.expireAt(key, time);
stringKeyRedisTemplate.expire(key, overdueTime, TimeUnit.SECONDS);
// 获取过期时间
stringKeyRedisTemplate.getExpire(keyObj, TimeUnit.SECONDS);
问题29、Spring Boot @DateTimeFormat 和 @JsonFormat 注解
@DateTimeFormat和 @JsonFormat用于标注在实体对象的日期变量上,例如:
@DateTimeFormat(pattern = "yyyy-MM-dd")
@JsonFormat(pattern = "yyyy-MM-dd")
private Date birthday;
@DateTimeFormat(pattern)用于将前端传过来的日期字符串自动转化为日期对象;
@JsonFormat(pattern)用于将数据库中取出来的日期对象自动调整为pattern格式的日期对象。
问题30、MyBatis Plus分页插件问题, Every derived table must have its own alias
项目中遇到SQL报错抛异常,报错内容如下。
[Code: 1248, SQL State: 42000] Every derived table must have its own alias
查看报错的SQL如下:
SELECT * FROM (
SELECT TMP_PAGE.*, ROWNUM ROW_ID FROM ......
很明显,ROWNUM是属于Oracle的语法,而把出错的语句放到Oracle环境下执行是没有问题的。而放在MySQL下才会有问题。而问题的根源在于MyBatis Plus分页插件所使用的方言导致的。因为MyBatis的子查询并不需要别名(alias)。当然,即使手动把SQL语句加上别名,执行SQL也依然会报其他错误,因为MySQL没有ROWNUM的概念。通常情况下,都会根据Every derived table must have its own alias到网上找解决方案,结果无一例外的提示需要给表加别名。
解决办法:
在分页插件的配置中,指定好数据库的类型。
springboot config类
/**
* mybatis-plus分页插件
*/
@Bean
public PaginationInterceptor paginationInterceptor() {
PaginationInterceptor page = new PaginationInterceptor();
page.setLimit(-1);
final String mySqlType="mysql";
if(url.contains(mySqlType)){
page.setDbType(DbType.MYSQL);
page.setCountSqlParser(new JsqlParserCountOptimize(true));
}else{
page.setDbType(DbType.ORACLE);
page.setCountSqlParser(new JsqlParserCountOptimize(true));
}
return page;
}
或者在xml配置中
<plugins>
<plugin interceptor="com.github.pagehelper.PageInterceptor">
<!-- 设置数据库类型 Oracle,Mysql,MariaDB,SQLite,Hsqldb,PostgreSQL六种数据库-->
<property name="helperDialect" value="oracle"/>
</plugin>
</plugins>
<databaseIdProvider type="DB_VENDOR">
<property name="MySQL" value="mysql"/>
<property name="Oracle" value="oracle" />
<property name="SQL Server" value="sqlserver"/>
<property name="DB2" value="DB2" />
</databaseIdProvider>
问题31、达梦数据库指定模式名【存疑】
JDBC URL属性为:schema,指定用户登录后的当前模式,默认为用户的默认模式。
JDBC URL为:jdbc:dm://ip:port?schema=模式名
String name="dm.jdbc.driver.DmDriver";
String url="jdbc:dm://192.168.15.35:5236?schema=TEST2"; //使用schema指定当前模式名
String user="TEST";
String password="123456789";
注意在mybatis-plus+druid的springboot后端框架中,使用该方式仍然读取的用户的默认模式,故该问题可能存在兼容性问题。
问题32、Redis集群下的过期监听事件notify-keyspace-events
针对单例redis的,换成redis集成环境,监听事件就失效了,只能重新写。
数据库通知介绍
数据库通知 是 Redis 2.8 版本新增加的功能,这个功能可以让客户端通过发布/订阅给定的频道或者模式,来获知数据库中键的变化,以及数据库中命令的执行情况。
分类:
键空间通知:某个键执行了什么命令(key-space notification)
**键事件通知:**某个命令被什么键执行了(key-event notification)
K 键空间通知,以 keyspace@ 为前缀
E 键事件通知, 以keyevent@ 为前缀
g del,expire,rename等无关的通用命令的集合
$ String命令
l List命令
s Set命令
h Hash命令
z 有序集合命令
x 过期事件(key过期时生成)
e 驱逐事件(内存满了,key被清除时)
A 以上 g$lshzxe的集合,AKE 代表接收全部的通知
第一步,redis配置文件的修改; 过期事件,属于键事件通知,因此在监听过期事件时,需要在集群中的每个redis的配置文件中写上:notify-keyspace-events Ex 默认notify-keyspace-events “",不接收任何通知。
第二步,测试代码;
在作者的原有部分的代码上进行了改造,实现了自己的业务逻辑。
package com.nrec.pcs9000.app.service;
import com.nrec.pcs9000.app.constants.AppConstant;
import io.lettuce.core.RedisURI;
import io.lettuce.core.cluster.RedisClusterClient;
import io.lettuce.core.cluster.models.partitions.RedisClusterNode;
import io.lettuce.core.cluster.pubsub.RedisClusterPubSubAdapter;
import io.lettuce.core.cluster.pubsub.StatefulRedisClusterPubSubConnection;
import io.lettuce.core.cluster.pubsub.api.async.NodeSelectionPubSubAsyncCommands;
import io.lettuce.core.cluster.pubsub.api.async.PubSubAsyncNodeSelection;
import io.lettuce.core.pubsub.RedisPubSubAdapter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.ApplicationArguments;
import org.springframework.boot.ApplicationRunner;
import org.springframework.stereotype.Service;
import javax.annotation.Resource;
/**
* 类<code>Doc</code>用于:监听守望位缓存{@link RedisClusterSubscribeService}过期事件,执行守望位跳转
*
* @author luohao
* @version 1.0
* @date 2022/2/16 15:32
*/
@Service
public class RedisClusterSubscribeService extends RedisPubSubAdapter implements ApplicationRunner {
private static final Logger log = LoggerFactory.getLogger(RedisClusterSubscribeService.class);
/**
* 过期事件监听通道
*/
private static final String EXPIRED_CHANNEL = "__keyevent@0__:expired";
@Value("${spring.redis.cluster.nodes}")
private String clusterNodes;
@Value("${spring.redis.password}")
private String password;
@Resource
private ICameraKeepWatchService keepWatchService;
@Override
public void run(ApplicationArguments args) {
log.info("监听Redis过期事件,用于守望位......");
//项目启动后就运行该方法
startListener();
}
/**
* 启动监听
*/
@SuppressWarnings("unchecked")
public void startListener() {
//redis集群监听
String[] redisNodes = clusterNodes.split(",");
//监听其中一个端口号即可
RedisURI redisURI = RedisURI.create("redis://" + redisNodes[0]);
redisURI.setPassword(password);
RedisClusterClient clusterClient = RedisClusterClient.create(redisURI);
StatefulRedisClusterPubSubConnection<String, String> pubSubConnection = clusterClient.connectPubSub();
//redis节点间消息的传播为true
pubSubConnection.setNodeMessagePropagation(true);
//过期消息的接受和处理
pubSubConnection.addListener(new RedisClusterPubSubAdapter() {
@Override
public void message(RedisClusterNode node, Object channel, Object message) {
String expiredKey = message.toString();
workingOnExpireKey(expiredKey);
}
});
//异步操作
PubSubAsyncNodeSelection<String, String> masters = pubSubConnection.async().masters();
NodeSelectionPubSubAsyncCommands<String, String> commands = masters.commands();
//设置订阅消息类型,一个或多个
commands.subscribe(EXPIRED_CHANNEL);
}
private void workingOnExpireKey(String expiredKey) {
// 无论是强制的还是普通守望位缓存过期,均调用预置位
if (expiredKey.contains(AppConstant.COMMON_KEEPWATCH_OVERDUE_TIME_KEY) || expiredKey.contains(AppConstant.FORCE_KEEPWATCH_OVERDUE_TIME_KEY)) {
keepWatchService.doKeepWatch(expiredKey);
}
}
}
问题33、@Scope(“prototype”)的正确用法——解决Bean的多例问题
1、Spring管理的某个Bean需要使用多例
可以使用@Scope("prototype"),注解在需要使用多例的这个类上。
2、问题升级:多个Bean的依赖链中,有一个需要多例
真实的Spring Web工程起码有Controller、Service、Dao三层,假如Controller层是单例,Service层需要多例,这时候应该怎么办呢?
成功方法一、在Controller和Service都加上注解,controller(@Autowired注入service)
直接在Service层加注解
@Scope("prototype"),失败。在Controller和Service都加上
@Scope("prototype"),成功。
Spring定义了多种作用域,可以基于这些作用域创建bean,包括:
- 单例( Singleton):在整个应用中,只创建bean的一个实例。
- 原型( Prototype):每次注入或者通过Spring应用上下文获取的时候,都会创建一个新的bean实例。
对于以上说明,我们可以这样理解:虽然Service是多例的,但是Controller是单例的。如果给一个组件加上@Scope("prototype")注解,每次请求它的实例,spring的确会给返回一个新的。问题是这个多例对象Service是被单例对象Controller依赖的。而单例服务Controller初始化的时候,多例对象Service就已经注入了;当你去使用Controller的时候,Service也不会被再次创建了(注入时创建,而注入只有一次)。
成功方法二、在Service都加上注解,controller(通过SpringBeanUtil.getBean注入service)
在Controller钟每次去请求获取Service实例,而不是使用@Autowired注入,成功。
3、技术总结
- 方法一,为了一个多例,让整个一串Bean失去了单例的优势;
- 方法二,破坏IOC注入的优美展现形式,和new一样不便于管理和修改。
Spring作为一个优秀的、用途广、发展时间长的框架,一定有成熟的解决办法。经过一番搜索,我们发现,注解@Scope("prototype")(这个注解实际上也可以写成@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE,使用常量比手打字符串不容易出错)还有很多用法。
首先value就分为四类:
- ConfigurableBeanFactory.SCOPE_PROTOTYPE,即“prototype”
- ConfigurableBeanFactory.SCOPE_SINGLETON,即“singleton”
- WebApplicationContext.SCOPE_REQUEST,即“request”
- WebApplicationContext.SCOPE_SESSION,即“session”
他们的含义是:
- singleton和prototype分别代表单例和多例;
- request表示请求,即在一次http请求中,被注解的Bean都是同一个Bean,不同的请求是不同的Bean;
- session表示会话,即在同一个会话中,被注解的Bean都是使用的同一个Bean,不同的会话使用不同的Bean。
使用session和request产生了一个新问题,生成controller的时候需要service作为controller的成员,但是service只在收到请求(可能是request也可能是session)时才会被实例化,controller拿不到service实例。为了解决这个问题,@Scope注解添加了一个proxyMode的属性,有两个值ScopedProxyMode.INTERFACES和ScopedProxyMode.TARGET_CLASS,前一个表示表示Service是一个接口,后一个表示Service是一个类。
本文遇到的问题中,将@Scope注解改成@Scope(value = WebApplicationContext.SCOPE_REQUEST, proxyMode = ScopedProxyMode.TARGET_CLASS)就可以使用注入@Autowired的方式来同样实现了。
问题34、时间格式与cron表达式
1、根据指定时间生成cron表达式
/**
* 通过输入指定日期时间生成cron表达式
* @param date
* @return cron表达式
*/
public String getCron(Date date){
String dateFormat="ss mm HH dd MM ? yyyy";
SimpleDateFormat sdf = new SimpleDateFormat(dateFormat);
String formatTimeStr = null;
if (date != null) {
formatTimeStr = sdf.format(date);
}
return formatTimeStr;
2、hutool提供的工具类
CronPatternUtil.matchedDates() 能够列举指定日期范围内所有匹配表达式的日期、
CronPattern.match() 判断给定时间是否匹配定时任务表达式
问题35、Spring JPA 使用注解映射MySQL数据库的Blob和Text类型数据
- Clob(Character Large Ojects)类型是长字符串类型,具体的java.sql.Clob, Character[], char[] 和 java.lang.String 将被持久化为 Clob 类型。
- Blob(Binary Large Objects)类型是字节类型,具体的java.sql.Blob, Byte[], byte[] 和 serializable type 将被持久化为 Blob 类型。
- @Lob 持久化为Blob或者Clob类型,根据get方法的返回值不同,自动进行Clob和Blob的转换。
- 因为这两种类型的数据一般占用的内存空间比较大,所以通常使用延迟加载的方式,与@Basic标记同时使用,设置加载方式为FetchType.LAZY。 参考: 浅谈JPA的Blob和Clob注解方法
在MySQL中Blob和Clob对应的的字段类型有
tinytext (tintblob)、text (blob)、mediumtext (mediumblob)和longtext (longblob) 参考: MySQL中tinytext、text、mediumtext和longtext详解
一般在java中Clob类型用String声明,Blob用byte[]声明MySQL数据库对应字段,例如:
@Lob
@Basic(fetch = FetchType.LAZY)
@Column(name = "f_task_content", nullable = false, columnDefinition = "Text")
private String taskContent;
问题36、去掉字符串中的回车、换行、制表符
若一个字符串存在\n(换行)\r(回车)\t(制表)符。那么即使相同内容的字符串(不含特殊符号),他们的equals方法也会不同。这就要求我们移除这些特殊符号。
/**
* 在正则表达式中\s表示所有的空格: 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。
* 使用正则表达式,移除换行符(且不移除空格)
*
* @param originalStr 原始字符串
* @return 移除换行\r、回车\n、制表\t符的字符串
*/
public static String removeRNT(String originalStr) {
if (originalStr == null || originalStr.isEmpty()) {
return originalStr;
}
return originalStr.replaceAll("[\t\n\r]","");s
}
/**
* 移除字符串中所有的空白格(包含换行\r、回车\n、制表\t符)
*
* @param str 原始串
* @return 无空格后的串
*/
public static String trimAllWhitespace(String str) {
if (str == null || str.isEmpty()) {
return str;
}
int len = str.length();
StringBuilder sb = new StringBuilder(str.length());
for (int i = 0; i < len; i++) {
char c = str.charAt(i);
if (!Character.isWhitespace(c)) {
sb.append(c);
}
}
return sb.toString();
}
移除特殊符号的时候,可以使用正则表达式,但是也要注意,不要把正常的空格符给移除。
问题37、解决POI读取Excel如何判断行是不是为空
public static boolean isRowEmpty(Row row) {
for (int c = row.getFirstCellNum(); c < row.getLastCellNum(); c++) {
Cell cell = row.getCell(c);
if (cell != null && cell.getCellType() != Cell.CELL_TYPE_BLANK){
return false;
}
}
return true;
}
问题38、忽略https证书:No subject alternative names present
做项目提供restful api,本地部署访问http://localhost:8080可以正确访问,当部署到一个高安全性的服务器上时,项目访问路径变成了https://xxx.xxx.xxx.xxx:xxxx,此时再次测试时会报错。
javax.net.ssl.SSLHandshakeException: java.security.cert.CertificateException: No subject alternative names present
private InputStream getUrlPictureStream(String urlPath) throws IOException, NoSuchAlgorithmException, KeyManagementException {
String fullUrl = "https://198.120.100.102" + urlStringEncode(urlPath);
return SslUtils.getUrlInputStream(fullUrl);
}
错误猜测为证书问题。因为本身https请求就对证书有要求,于是将代码修改如下,可以绕过证书问题
package com.nrec.pcs9000.app.util;
/**
* @author luohao
* @date 2021/9/27 21:18
*/
import javax.net.ssl.*;
import java.io.IOException;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
import java.security.KeyManagementException;
import java.security.NoSuchAlgorithmException;
import java.security.SecureRandom;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
public class SslUtils {
private static final NullHostNameVerifier nullHostNameVerifier = new NullHostNameVerifier();
private static final TrustManager[] trustAllCerts = new TrustManager[]{new X509TrustManager() {
@Override
public void checkClientTrusted(X509Certificate[] chain, String authType) throws CertificateException {
}
@Override
public void checkServerTrusted(X509Certificate[] chain, String authType) throws CertificateException {
}
@Override
public X509Certificate[] getAcceptedIssuers() {
return null;
}
}};
private SslUtils() {
}
public static InputStream getUrlInputStream(String urlStr)
throws IOException, KeyManagementException, NoSuchAlgorithmException {
HttpsURLConnection.setDefaultHostnameVerifier(nullHostNameVerifier);
SSLContext sc = SSLContext.getInstance("TLS");
sc.init(null, trustAllCerts, new SecureRandom());
HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory());
URL url = new URL(urlStr);
// 打开restful链接
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
// conn.setRequestMethod("POST");// POST GET PUT DELETE
// 设置访问提交模式,表单提交
// conn.setRequestProperty("Content-Type", "application/json;charset=utf-8");
conn.setConnectTimeout(130000);// 连接超时 单位毫秒
conn.setReadTimeout(130000);// 读取超时 单位毫秒
// 读取请求返回值
return conn.getInputStream();
}
private static class NullHostNameVerifier implements HostnameVerifier {
/*
* (non-Javadoc)
*
* @see javax.net.ssl.HostnameVerifier#verify(java.lang.String,
* javax.net.ssl.SSLSession)
*/
@Override
public boolean verify(String arg0, SSLSession arg1) {
return true;
}
}
}
问题39、knife4j 实现文件下载及图片预览
目前SwaggerBootstrapUi以及knife4j支持的响应类型如下:
| 类型 | 说明 |
|---|---|
| application/octet-stream | 二进制流 |
| image/png | 图片 |
| image/jpg | 图片 |
| image/jpeg | 图片 |
| image/gif | 图片 |
特别需要注意的是:不管是文件下载或者是需要图片预览,都需要在接口中指定接口的produces,否则不能达到预期效果,接口的produces可参考上面表格中列出项.
@ApiOperation(value = "下载测试-有参数+请求头版",position = 3)
@GetMapping(value = "/downloadFileAndParam2",produces = "application/octet-stream")
public void postRequest3AndParam(@RequestHeader(value = "uud") String uud,@RequestParam(value = "name") String name, HttpServletRequest request, HttpServletResponse response){
logger.info("header:{}",uud);
download(name,response);
}
@Api(value = "图片预览",tags = "图片预览")
@RestController
@RequestMapping("/api/image")
public class ImageController {
@GetMapping(value = "/preview",produces = "image/jpeg")
public void preview(HttpServletRequest request, HttpServletResponse response) throws IOException {
//more....
}
}
问题40、lombok使用
1、使用@RequiredArgsConstructor+final代替@Autowired和@Resource
@NoArgsConstructor后会 生成无参的构造方法
@RequiredArgsConstructor会将类的每一个final字段或者non-null字段生成一个构造方法
@AllArgsConstructor 生成一个包含过所有字段的构造方法。
@AllArgsConstructor 和@RequiredArgsConstructor都可以用来替换@Autowired写法,区别在@RequiredArgsConstructor必须要有final修饰。
遇到坑,使用
@AllArgsConstructor后,@Value会失效,获取不到值。使用@RequiredArgsConstructor则正常。今后注入service、mapper等都使用@RequiredArgsConstructor好了。
Springboot官方建议使用final来修饰成员变量,然后通过构造方法来进行注入原因:final修饰的成员变量是不能够被修改的,反射那就没办法了
下面就是Spring推荐的写法
@Service
public class OrderService {
private final UserService userService;
@Autowired
public OrderService(UserService userService) {
this.userService = userService;
}
}
@RequiredArgsConstructor也是在类上使用,但是这个注解可以生成带参或者不带参的构造方法。
若带参数,只能是类中所有带有 @NonNull注解的和以final修饰的未经初始化的字段
@Service
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class OrderService {
//这里必须是final,若不使用final,用@NotNull注解也是可以的
private final UserService userService;
@NotNull
private PayService payService;
}
@Service
@RequiredArgsConstructor
public class OrderService {
//这里必须是final,若不使用final,用@NotNull注解也是可以的
private final UserService userService;
@NotNull
private PayService payService;
}
2、@SneakyThrows 抛出异常
@SneakyThrows
private void checkCode(ServerHttpRequest request) {
String code = request.getQueryParams().getFirst("code");
if (StrUtil.isBlank(code)) {
throw new ValidateCodeException("验证码不能为空");
}
redisTemplate.delete(key);
}
// 不使用就要加这个抛出
private void checkCode(ServerHttpRequest request) throws ValidateCodeException {
String code = request.getQueryParams().getFirst("code");
if (StrUtil.isBlank(code)) {
throw new ValidateCodeException("验证码不能为空");
}
}
3、@UtilityClass 工具类再也不用定义static的方法了,直接就可以Class.Method 使用
@UtilityClass
public class Utility {
public String getName() {
return "name";
}
}
public static void main(String[] args) {
System.out.println(Utility.getName());
}
4、@CleanUp: 清理流对象,不用手动去关闭流,多么优雅
@Cleanup
OutputStream outStream = new FileOutputStream(new File("text.txt"));
@Cleanup
InputStream inStream = new FileInputStream(new File("text2.txt"));
byte[] b = new byte[65536];
while (true) {
int r = inStream.read(b);
if (r == -1) break;
outStream.write(b, 0, r);
}
5、@EqualsAndHashCode:生成equals和hashCode方法
exclude方式
@EqualsAndHashCode
public class EqualsAndHashCodeExample {
private transient int transientVar = 10;
private String name;
private double score;
@EqualsAndHashCode.Exclude private Shape shape = new Square(5, 10); // 这个属性被排除
private String[] tags;
@EqualsAndHashCode.Exclude private int id; // 这个属性被排除
public String getName() {
return this.name;
}
@EqualsAndHashCode(callSuper=true) // 调用父类属性
public static class Square extends Shape {
private final int width, height;
public Square(int width, int height) {
this.width = width;
this.height = height;
}
}
}
include的方式
@EqualsAndHashCode(onlyExplicitlyIncluded = true, callSuper = false)
@TableName("point_acquire")
@ApiModel(value = "PointAcquire对象", description = "采集点位表")
public class PointAcquire extends SuperEntity<PointAcquire> {
private static final long serialVersionUID = 1L;
@Excel(name = "")
@TableId(value = "id", type = IdType.ASSIGN_UUID)
private String id;
@ApiModelProperty(value = "采集点位编号")
@Excel(name = "采集点位编号")
@EqualsAndHashCode.Include
private String acquirePointCode;
...
}
6、@FieldNameConstants 获取类的属性名称
直接使用效果
import lombok.experimental.FieldNameConstants;
import lombok.AccessLevel;
@FieldNameConstants
public class FieldNameConstantsExample {
private final String iAmAField;
private final int andSoAmI;
// 添加 @FieldNameConstants.Exclude 这个注解表示该属性名不需要提供属性名
@FieldNameConstants.Exclude
private final int asAmI;
}
代码效果
public class FieldNameConstantsExample {
private final String iAmAField;
private final int andSoAmI;
private final int asAmI;
public static final class Fields {
public static final String iAmAField = "iAmAField";
public static final String andSoAmI = "andSoAmI";
}
}
一些定制需求
-
如果希望使用枚举类型: @FieldNameConstants(asEnum = true)
-
如果希望使用是全大写的输出结果,修改lombok配置,注解方式无法配置!
lombok.fieldNameConstants.uppercase = true -
默认内部类名是 Fields ,而且是 public。如果想临时修改,可以使用注解配置:@FieldNameConstants(innerTypeName = “FieldNames”, access = AccessLevel.PACKAGE); 如果想统一修改内部类名,可以修改 lombok 配置文件
lombok.fieldNameConstants.innerTypeName
7、子类继承父类,父类属性不生效
子类增加:
@ToString(callSuper = true)
@EqualsAndHashCode(callSuper = true)
问题41、使用Optional和stream解决List的NPE问题
如果整个 list 可能为 null,用 Optional 包装一下
如果 list 中的某个 object 可能为 null,用 .filter(Objects::nonNull)
List<Person> personList = new ArrayList<>();
personList.add(new Person());
personList.add(null);
personList.add(new Person("小明", 10));
personList.add(new Person("小红", 12));
Optional.ofNullable(personList).orElseGet(() -> {
System.out.println("personList 为 null !");
return new ArrayList<>();
}).stream().filter(Objects::nonNull).forEach(person -> {
System.out.println(person.getName());
System.out.println(person.getAge());
});
问题42、SpringBoot上传文件大小限制的配置
使用SpingBoot框架上传文件时,如果文件大小超过了1MB,会报错:
Maximum upload size exceeded; nested exception is java.lang.IllegalStateException: org.apache.tomcat.util.http.fileupload.FileUploadBase$FileSizeLimitExceededException:
The field file exceeds its maximum permitted size of 1048576 bytes
原因是SpringBoot内置的Tomcat的文件传输默认单个文件最大1M,单次请求文件总数大小为10M。 解决方法: 可以在SpingBoot的application.yml配置文件中进行修改
SpingBoot2.0版本之前:
spring:
http:
multipart:
maxFileSize: 20MB #单个文件最大为20M
maxRequestSize: 20MB #单次请求文件总数大小为20M
SpingBoot2.0版本之后:
spring:
servlet:
multipart:
max-file-size: 20MB #单个文件最大为20M
max-request-size: 20MB #单次请求文件总数大小为20M
问题43、mybatisplus调用saveOrUpdateBatch报NPE问题
注意可能不是调用传入的List为空的所导致的,
建议进入saveOrUpdateBatch的源码进行逐步调试,此次问题是由getById导致的,原因是:getById时调用数据库sql查找对象,由于mybatisPlus的下划线转驼峰的设定,有个字段a__b_c转为驼峰后又在getById调用时转回下划线变成了a_b_c,导致列名没有匹配上。
无效的列名:【xxxxx】
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveOrUpdateBatch(Collection<T> entityList, int batchSize) {
TableInfo tableInfo = TableInfoHelper.getTableInfo(entityClass);
Assert.notNull(tableInfo, "error: can not execute. because can not find cache of TableInfo for entity!");
String keyProperty = tableInfo.getKeyProperty();
Assert.notEmpty(keyProperty, "error: can not execute. because can not find column for id from entity!");
return executeBatch(entityList, batchSize, (sqlSession, entity) -> {
Object idVal = ReflectionKit.getMethodValue(entityClass, entity, keyProperty);
if (StringUtils.checkValNull(idVal) || Objects.isNull(getById((Serializable) idVal))) {
sqlSession.insert(tableInfo.getSqlStatement(SqlMethod.INSERT_ONE.getMethod()), entity);
} else {
MapperMethod.ParamMap<T> param = new MapperMethod.ParamMap<>();
param.put(Constants.ENTITY, entity);
sqlSession.update(tableInfo.getSqlStatement(SqlMethod.UPDATE_BY_ID.getMethod()), param);
}
});
}
至于报NPE的原因在于mybatisPlus进行了异常捕获。 throw Objects.requireNonNull(myBatisExceptionTranslator.translateExceptionIfPossible((RuntimeException) unwrapped));在这里将捕获的无效的列名的异常,给转化成了requireNonNull的异常抛出,故显示为NPE问题。
@Deprecated
protected boolean executeBatch(Consumer<SqlSession> consumer) {
SqlSessionFactory sqlSessionFactory = SqlHelper.sqlSessionFactory(entityClass);
SqlSessionHolder sqlSessionHolder = (SqlSessionHolder) TransactionSynchronizationManager.getResource(sqlSessionFactory);
boolean transaction = TransactionSynchronizationManager.isSynchronizationActive();
if (sqlSessionHolder != null) {
SqlSession sqlSession = sqlSessionHolder.getSqlSession();
//原生无法支持执行器切换,当存在批量操作时,会嵌套两个session的,优先commit上一个session
//按道理来说,这里的值应该一直为false。
sqlSession.commit(!transaction);
}
SqlSession sqlSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
if (!transaction) {
log.warn("SqlSession [" + sqlSession + "] was not registered for synchronization because DataSource is not transactional");
}
try {
consumer.accept(sqlSession);
//非事物情况下,强制commit。
sqlSession.commit(!transaction);
return true;
} catch (Throwable t) {
sqlSession.rollback();
Throwable unwrapped = ExceptionUtil.unwrapThrowable(t);
if (unwrapped instanceof RuntimeException) {
MyBatisExceptionTranslator myBatisExceptionTranslator
= new MyBatisExceptionTranslator(sqlSessionFactory.getConfiguration().getEnvironment().getDataSource(), true);
throw Objects.requireNonNull(myBatisExceptionTranslator.translateExceptionIfPossible((RuntimeException) unwrapped));
}
throw ExceptionUtils.mpe(unwrapped);
} finally {
sqlSession.close();
}
}
问题44、restTemplate调用post接口
postForObject及其他方法中的Object request,传入param和header实例
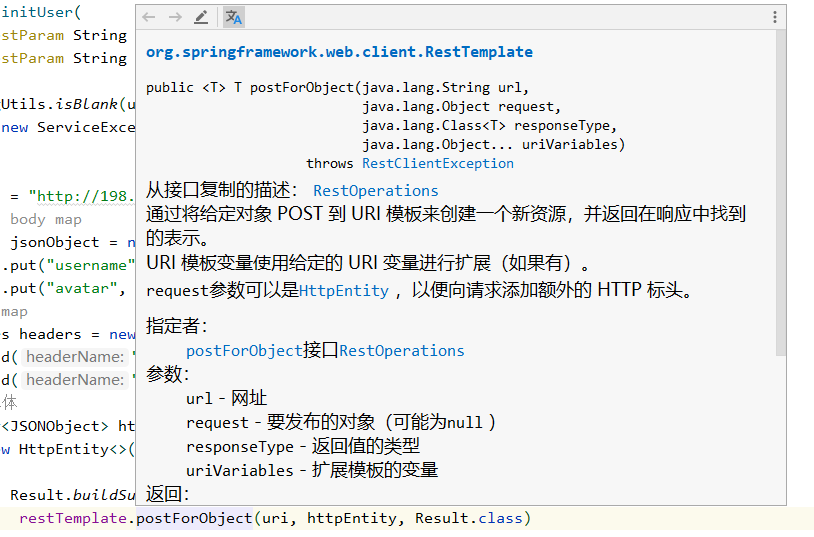
if (StringUtils.isBlank(username) || StringUtils.isBlank(orgName)) {
throw new ServiceException("接口参数不能为空");
}
// uri
String uri = "http://198.120.100.105:18467/user/SyncUser";
// request body map
JSONObject jsonObject = new JSONObject();
jsonObject.put("username", username);
jsonObject.put("avatar", orgName);
// header map
HttpHeaders headers = new HttpHeaders();
headers.add("code", "1");
headers.add("INNER_ACCESS", "true");
// 组装请求体
HttpEntity<JSONObject> httpEntity =
new HttpEntity<>(jsonObject, headers);
try {
return Result.buildSuccess(
restTemplate.postForObject(uri, httpEntity, Result.class)
);
} catch (Exception e) {
e.printStackTrace();
}
return Result.buildFailed();
问题45、@ConfigurationProperties自定义配置属性类并实现IDE自动提示
配置类声明如下,Spring 宽松绑定规则 (relaxed binding):能够支持属性不严格绑定,不一定限定在驼峰。
@Component
// 或者将@Component替换为@EnableConfigurationProperties(value = TestProperties.class)
@ConfigurationProperties(prefix = "test")
// @RefreshScope
@Getter
@Setter
public class TestProperties {
/**作者*/
private String username;
private Integer port = 8080;
private String pass;
}
配合spring-boot-configuration-processor使用,引入maven依赖,并且maven reimport
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
声明好配置类TestProperties之后,maven rebuild即可在yaml文件中自动映射到test
问题46、springboot热部署
覆盖的范围:修改的类、配置文件,对修改的这些文件进行重新加载。
1. 引入spring boot devtools,添加maven依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
2. 在maven中添加插件
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<!--fork : 如果没有该项配置,则devtools不会起作用,即应用不会restart -->
<fork>true</fork>
<addResources>true</addResources><!--支持静态文件热部署-->
</configuration>
</plugin>
问题47、Spring Boot启动时执行初始化操作
1、@PostConstruct
对于注入到Spring容器中的类,在其成员函数前添加@PostConstruct注解,则在执行Spring beans初始化时,就会执行该函数。
但由于该函数执行时,其他Spring beans可能并未初始化完成,因此在该函数中执行的初始化操作应当不依赖于其他Spring beans。
@Component
public class Construct {
@PostConstruct
public void doConstruct() throws Exception {
System.out.println("初始化:PostConstruct");
}
}
2、@CommandLineRunner
CommandLineRunner是Spring提供的接口,定义了一个run()方法,用于执行初始化操作
@Component
public class InitCommandLineRunner implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("初始化:InitCommandLineRunner");
}
}
CommandLineRunner的时机为Spring beans初始化之后,因此CommandLineRunner的执行一定是晚于@PostConstruct的。
若有多组初始化操作,则每一组操作都要定义一个CommandLineRunner派生类并实现run()方法。这些操作的执行顺序使用@Order(n)来设置,n为int型数据
@Component
@Order(99)
public class CommandLineRunnerA implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("初始化:CommandLineRunnerA");
}
}
@Component
@Order(1)
public class CommandLineRunnerB implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("初始化:CommandLineRunnerB");
}
}
如上,会先执行CommandLineRunnerB的run(),再执行CommandLineRunnerA的run()。@Order(n)中的n较小的会先执行,较大的后执行。n只要是int值即可,无需顺序递增。
3、ApplicationRunner
ApplicationRunner接口与CommandLineRunner接口类似,都需要实现run()方法。二者的区别在于run()方法的参数不同:
@Component
public class InitApplicationRunner implements ApplicationRunner {
@Override
public void run(ApplicationArguments applicationArguments) throws Exception {
System.out.println("初始化:InitApplicationRunner");
}
}
ApplicationRunner接口的run()参数为ApplicationArguments对象,因此可以获取更多项目相关的内容。
ApplicationRunner接口与CommandLineRunner接口的调用时机也是相同的,都是Spring beans初始化之后。
因此ApplicationRunner接口也使用@Order(n)来设置执行顺序。
问题50、springboot单元测试
1、在src目录下建立 test.java 目录,作为单元测试根目录
2、创建父类,在需要创建单元测试的类上alt+enter,create tests,选择superClass和需要单元测试的方法
/**
* 类 AppApplicationTests<code>Doc</code>用于:单元测试主类
*
* @author 罗皓
* @version 1.0
* @date 2022/5/12 14:24
*/
@SpringBootTest
@RunWith(SpringRunner.class)
@ActiveProfiles(value = "test")
//由于是Web项目,Junit需要模拟ServletContext,因此我们需要给我们的测试类加上@WebAppConfiguration。
@WebAppConfiguration
public class AppApplicationTests {
@Before
public void init() {
System.out.println("开始测试-----------------");
}
@After
public void after() {
System.out.println("测试结束-----------------");
}
}
3、针对controller,示例如下
/**
* 类 OpsDevConfigControllerTest<code>Doc</code>用于:Controller测试包
*
* @author 罗皓
* @version 1.0
* @date 2022/5/12 14:26
*/
@AutoConfigureMockMvc
class OpsDevConfigControllerTest extends AppApplicationTests {
private MockMvc mockMvc;
@BeforeEach
public void setUp(WebApplicationContext context) {
//集成Web环境方法
mockMvc = MockMvcBuilders.webAppContextSetup(context).build();
}
@Test
// @Ignore
void getOpsDevConfigDeviceType() throws Exception {
mockMvc.perform(MockMvcRequestBuilders.get("/ops-dev-config/device-type/access"))
.andDo(MockMvcResultHandlers.print())
.andExpect(MockMvcResultMatchers.status().isOk());
}
@Test
void getOpsDevConfigById() throws Exception {
MvcResult mvcResult = mockMvc.perform(MockMvcRequestBuilders.get("/ops-dev-config/333/access"))
.andDo(MockMvcResultHandlers.print())
.andExpect(MockMvcResultMatchers.status().isOk())
.andReturn();
System.out.println("=== 打印 ===");
System.out.println(mvcResult.getResponse().getContentAsString());
}
}
4、针对service,示例如下
/**
* 类 OpsDevConfigServiceImplTest<code>Doc</code>用于:TODO
*
* @author 罗皓
* @version 1.0
* @date 2022/5/12 14:42
*/
class OpsDevConfigServiceImplTest extends AppApplicationTests {
@Autowired
private IOpsDevConfigService iOpsDevConfigService;
@Test
void getOpsDevConfigById() {
assertNotNull(iOpsDevConfigService.getOpsDevConfigById("333"));
}
@Test
void getAllDeviceType() {
List<String> allDeviceType = iOpsDevConfigService.getAllDeviceType();
System.out.println(allDeviceType);
}
}
问题51、mybatis-plus 3 IService事务分析
mybatis-plus 3已经引入了spring-tx,记得要在配置类中通过注解启用事务,spring-tx的@EnableTransactionManagement注解。
提供IService接口和ServiceImpl实现,其中只有标注了@Transactional(rollbackFor = Exception.class)的接口才做事务的回滚,基本为batch等需要执行批量操作的接口。
@Transactional默认回滚的是RuntimeException也就是说如果抛出的不是RuntimeException的异常,数据库是不会回滚的。但是所幸的是,在spring框架下,所有的异常都被org.springframework重写为RuntimeException,因此不需要太担心- 还有如果在异常发生时,程序员自己手动捕获处理了,异常也不会回滚
- 如果使用的是统一异常处理,继承了
RuntimeException,你只管直接抛异常就行,回滚、日志、统一异常都已经处理好了
问题52、stream
1、stream流操作
stream的降序排序和之前我们通过重写Comparable接口,实现降排相比,要节省很多代码,而用stream分页,一般用来裁剪数据。
排序
List<Student newList = new ArrayList<>(10);
//升序
list.stream().sorted((v1,v2)->v1.getId().compareTo(
v2.getId()
)).collect(Collectors.toList());
//降序
list.stream().sorted((v1,v2)->v2getId().compareTo(
v1.getId()
)).collect(Collectors.toList());
//根据子对象id,升序排序,Student对象中还有一个Boy的对象属性
list.stream().sorted((v1,v2)->v1.getBoy().getbId().compareTo(
v2.getBoy().getbId()
)).collect(Collectors.toList());
分页
skip:跳过n个元素,limit裁剪大小,currentPage当前页,pageSize当前页大小。
list.stream().skip((currentPage-1)*pageSize).limit(pageSize).
collect(Collectors.toList());
2、对象List集合各种操作
==注意:使用distinct、contains时候需要实现bean类的equals、hashCode方法==
如果是使用的lombok,可以参照这种用法,include如下
@EqualsAndHashCode(onlyExplicitlyIncluded = true, callSuper = false)
@TableName("point_acquire")
@ApiModel(value = "PointAcquire对象", description = "采集点位表")
public class PointAcquire extends SuperEntity<PointAcquire> {
private static final long serialVersionUID = 1L;
@Excel(name = "")
@TableId(value = "id", type = IdType.ASSIGN_UUID)
private String id;
@ApiModelProperty(value = "采集点位编号")
@Excel(name = "采集点位编号")
@EqualsAndHashCode.Include
private String acquirePointCode;
...
}
交集(listA ∩ ListB):
List<Person> listC = listA.stream().filter(item -> listB.contains(item)).collect(Collectors.toList());
listC中的元素有:属性name值为 aa, bb, cc 的对象。
并集(listA ∪ listB):
//先合体
listA.addAll(listB);
//再去重
List<Person> listC = listA.stream().distinct().collect(Collectors.toList());
listC中的元素有:属性name值为 aa, bb, cc ,dd的对象。
差集(listA - listB):
List<Person> listC = listA.stream().filter(item -> !listB.contains(item)).collect(Collectors.toList());
listC中的元素有:属性name值为 dd的对象。
过滤筛选:
List<Order> orders = Lists.newArrayList();
// 筛选总金额大于1000的订单
orders = orders.stream().filter(item -> item.getAllAmt() > 1000.00f).collect(Collectors.toList());
分组:
List<Order> orders = Lists.newArrayList();
// 按照订单类型分组
Map<String, List<Order>> orderGroupMap = orders.stream().collect(Collectors.groupingBy(Order::getType));
去重:
List<Order> orders = Lists.newArrayList();
// 按照订单编号去重
orders = orders.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(()
-> new TreeSet<>(Comparator.comparing(Order::getNum))), ArrayList::new));
// 按照订单编号和类型去重
orders = orders.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(()
-> new TreeSet<>(Comparator.comparing(o -> o.getNum() + ";" + o.getType()))), ArrayList::new));
List 转 Map :
List<Order> orders = Lists.newArrayList();
// 将订单集合转换成订单编号-应付金额 map,注意订单编号作为 key 不能重复,应先做去重处理
Map<String, Float> numPayMap = orders.stream().collect(Collectors.toMap(Order::getNum, Order::getPayAmt));
// 用 id 做 key 将 List 转成 Map
Map<Long, Order> orderMap = orders.stream().collect(Collectors.toMap(Order::getId, item -> item));
排序:
List<Order> orders = Lists.newArrayList();
// 按照订单总金额从高到低排序
// 方式一
orders.sort((o1, o2)
-> o1.getAllAmt() == null ? 1 : (o2.getAllAmt() == null ? -1 : o2.getAllAmt().compareTo(o1.getAllAmt())));
// 方式二
orders.sort(Comparator.comparing(Order::getAllAmt, (o1, o2)
-> o1 == null ? 1 : (o2 == null ? -1 : o2.compareTo(o1))));
// 方式三 (allAmt 字段不能为 null, null 会导致排序失败)
orders.sort(Comparator.comparing(Order::getAllAmt).reversed());
// 先按照订单类型排序,再按照订单应付金额从高到低排序
orders.sort(Comparator.comparing(Order::getType, (o1, o2)
-> o1 == null ? 1 : (o2 == null ? -1 : o1.compareTo(o2))).thenComparing((o1, o2)
-> o1.getPayAmt() == null ? 1 : (o2.getPayAmt() == null ? -1 : o2.getPayAmt().compareTo(o1.getPayAmt()))));
统计计数:
List<Order> orders = Lists.newArrayList();
// 统计所有订单的总金额
// 求和
Double sum = orders.stream().filter(item -> item.getAllAmt() != null).mapToDouble(Order::getAllAmt).sum();
// 最大总金额
OptionalDouble max = orders.stream().filter(item -> item.getAllAmt() != null).mapToDouble(Order::getAllAmt).max();
// 防止没有订单数据的处理
Double maxAllAmt = max.isPresent() ? max.getAsDouble() : 0;
// 最小总金额
OptionalDouble min = orders.stream().filter(item -> item.getAllAmt() != null).mapToDouble(Order::getAllAmt).min();
// 平均总金额
OptionalDouble average = orders.stream().filter(item -> item.getAllAmt() != null).mapToDouble(Order::getAllAmt).average();
Stream中直接是取不到当前变量的索引值的,需要变相获取,这里提供2种方法
public static void main(String[] args) {
Integer[] inputArray = new Integer[]{1, 3, 5, 7, 9};
Integer[] out = new Integer[inputArray.length-1];
//方法一 index就是自增索引
AtomicInteger index=new AtomicInteger(0);
Arrays.stream(inputArray).map(x->x+index.getAndIncrement());
//方法二
IntStream.range(0,inputArray.length).mapToObj(x->inputArray[x]).collect(Collectors.toList());
}
问题53、list 删除元素
最好使用迭代器 iterator
Iterator<?> it = response.iterator();
while (it.hasNext()) {
JSONObject jsonObject = (JSONObject) it.next();
if (!status.equals(jsonObject.getString("status"))) {
it.remove();
}
}
Iterator.remove() 方法会在删除当前迭代对象的同时,会保留原来元素的索引。所以用迭代删除元素是最保险的方法,建议大家使用List过程,这其实和list.remove(index) 方法类似,只不过iterator内部帮我们做了类似i-1的操作。推荐使用这种做法,因为我们不保证每次都记得手动把下标 index 减去1。
问题54、fastjson
各个对象转换
字符串、JSONObject、JSONarray
String json="{\"name\":\"刘德华\",\"age\":35,\"some\":[{\"k1\":\"v1\",\"k2\":\"v2\"},{\"k3\":\"v3\",\"k4\":\"v4\"}]}";
JSONObject jso=JSON.parseObject(json);//json字符串转换成jsonobject对象
JSONArray jsarr=jso.getJSONArray("some");//jsonobject对象取得some对应的jsonarray数组
JSONObject ao=jsarr.getJSONObject(0);//jsonarray对象通过getjsonobjext(index)方法取得数组里面的jsonobject对象
String vString=ao.getString("k1");//jsonobject对象通过key直接取得String的值
1.Map转JSON
Map<String, Object> map = new HashMap<String, Object>();
map.put("username", "yaomy");
map.put("password", "123");
JSONObject json = new JSONObject(map);
2.JSON转String
JSONObject json = new JSONObject();
json.put("username", "yaomy");
json.put("password", "123");
json.toJSONString();
3.JSON转Map
JSONObject json = new JSONObject();
json.put("username", "yaomy");
json.put("password", "123");
Map<String, Object> map = (Map<String, Object>)json;
4.String转JSON
String str = "{\"username\":\"yaomy\",\"password\":\"123\"}";
JSONObject json = JSONObject.parseObject(str);
5.JSONObject转JAVABEAN
Person person = JSONObject.toJavaObject(jsonObject, Person.class);
6.JAVABEAN转JSONObject(将bean转为JSON)
String jsonString=JSONObject.toJSONString(param);
JSONObject jSONObject=JSONObject.parseObject(jsonString);
JSONObject jsonObject = (JSONObject) JSONObject.toJSON(person);
7.javabean转string
JSON.toJSONString(user)
将Long类型转成String
前后端交互的时候,由于Long类型返回给前端时,如果数值过大,会导致精度丢失,后面几位会变成0,这时候就需要把Long转成String类型的返回给前端页面。
这时候如果专门为其写一个属性来存储,比较麻烦,需要改动的文件比较多。这时候可以使用fastJson里的标签
@JSONField(serializeUsing = ToStringSerializer.class)
只要在model类上的Long字段加上这个标签,则会返回前端时,把Long转成String
要注意的一点是。serializeUsing 这个属性是在fastjson 1.2.16后才有的。要检查下fastJson的版本
自定义Date类型反序列化
在最新的fastjson库里(1.2.38, Sep, 2017)没有DateFormatDeserializer类或者DateDeserializer类。通过查看源代码,发现目前使用:com.alibaba.fastjson.serializer.DateCodec。
自定义类SecondDeserializer继承DateCodec,然后重写cast方法,如下:
public class SecondDeserializer extends DateCodec {
public final static SecondDeserializer instance = new SecondDeserializer();
@Override
public <T> T cast(DefaultJSONParser parser, Type clazz, Object fieldName, Object val){
long value = Long.valueOf(String.valueOf(val)) * 1000;
return super.cast(parser, clazz, fieldName, value);
}
}
这样,当json传来是的秒,能够转化为java中的Date类。
返回结果为null属性不显示解决方法
返回时null属性不显示:String str = JSONObject.toJSONString(obj); 返回为null属性显示:String str = JSONObject.toJSONString(obj,SerializerFeature.WriteMapNullValue); Fastjson的SerializerFeature序列化属性
QuoteFieldNames———-输出key时是否使用双引号,默认为true。
WriteMapNullValue——–是否输出值为null的字段,默认为false。
WriteNullNumberAsZero—-数值字段如果为null,输出为0,而非null。
WriteNullListAsEmpty—–List字段如果为null,输出为[],而非null。
WriteNullStringAsEmpty—字符类型字段如果为null,输出为”“,而非null。
WriteNullBooleanAsFalse–Boolean字段如果为null,输出为false,而非null。
问题55、Comparator升序降序的记法
直接给出结论。从交换的角度去思考排序。
实现Comparator接口,必须实现下面这个函数:
@Override
public int compare(CommentVo o1, CommentVo o2) {
return o1.getTime().compareTo(o2.getTime());
}
这里o1表示位于前面的对象,o2表示后面的对象
- 返回-1(或负数),表示不需要交换01和02的位置,o1排在o2前面,asc
- 返回1(或正数),表示需要交换01和02的位置,o1排在o2后面,desc